The ask. "Several of our teams call Amazon Bedrock through one shared gateway. The bill comes back as one number. We need to see token usage and cost broken out per team, without standing up a separate gateway or a separate set of credentials for each one."
The answer pairs two things that already exist. Bedrock has application inference profiles, a per-application handle you tag for cost allocation. agentgateway records token usage per request and labels it with the model that was called. Give each team its own application inference profile, send the team's profile as the model, and the same usage is attributed per team on both sides of the gateway.
What you'll build
client · per team
Team workload
Calls /v1/chat/completions on the gateway. The
model field carries that team's Bedrock application
inference profile ARN. No AWS credentials on the client.
gateway · agentgateway-system
agentgateway
One AgentgatewayBackend for Bedrock with the model left
unset, so it comes from each request. Signs the call with the AWS
credentials in a Secret and records token usage labelled by model.
model · Amazon Bedrock
Bedrock
The Converse API. Each team's application inference profile resolves to the same underlying model but carries that team's cost-allocation tags.
One kind cluster, one gateway, one backend. Two teams in this lab,
finance and engineering, each with its own application
inference profile. Add a team by creating one more profile; nothing in the
gateway changes.
What Amazon Bedrock Mantle is, and how it helps
Amazon Bedrock Mantle is the serving layer that puts OpenAI-compatible (Chat
Completions, Responses) and Anthropic-compatible (Messages) APIs in front of
Bedrock, reached at bedrock-mantle.<region>.api.aws/v1 with
a bearer token. The point is portability: code already written against the
OpenAI or Anthropic SDK moves onto Bedrock by changing only the base URL and
the key, with no rewrite. It also brings service tiers and per-customer
isolation for inference at scale.
Mantle is the OpenAI-compatible front door to Bedrock. This lab reaches
Bedrock through agentgateway's native bedrock provider, which
speaks the Converse API directly and carries inference profiles cleanly, so
the per-team cost story below works the same regardless of which API shape
your clients prefer. The Mantle endpoint remains available as an
OpenAI-compatible ingress for teams that want it; the gateway is where the
common controls and the per-team accounting live either way.
Inference profiles, ARNs, and the Converse API
A Bedrock inference profile is a handle for a model that adds routing and accounting on top of a raw model id. There are two kinds, and the difference matters here.
- Cross-region (system) profiles carry a geography prefix,
such as
us.anthropic.claude-haiku-4-5-20251001-v1:0. They spread a request across the regions in that geography for capacity and resilience. - Application inference profiles are ones you create by
copying a system profile and attaching cost-allocation tags, for example
team=finance. They are referenced only by ARN, such asarn:aws:bedrock:us-east-1:<account-id>:application-inference-profile/<id>. This is the unit AWS attributes cost to.
The string you send as the model is one of these profiles. AWS
meters usage against it, and agentgateway records it as the
gen_ai_request_model on the token metric. So one identifier does
double duty: it is the AWS cost-allocation key and the gateway's metric label.
Under the gateway, the call goes to Bedrock's Converse API,
the unified message API that works consistently across model providers and
carries inference profiles, including application profiles. agentgateway's
bedrock provider uses Converse for you, so the client just sends
a chat-completions request with the profile in the model field.
Why profile cost per team
When many teams share one route to Bedrock, the default is a single undifferentiated bill and one aggregate token count. There is no way to answer "which team spent this." Putting agentgateway in front gives one place for authentication, guardrails, rate limits and routing, and one place to meter the traffic. Pairing that with one application inference profile per team gives attribution on two independent layers:
- In the gateway, in real time: the
agentgateway_gen_ai_client_token_usagemetric splits by team via thegen_ai_request_modellabel, so a Grafana panel shows tokens per team without waiting on a billing export. - In AWS, in dollars: the application inference profile's cost-allocation tag surfaces the team in AWS Cost Explorer and the Cost and Usage Report.
What's needed in AWS
Three things, all on the AWS side and all reusable across as many teams as you want to profile.
- Model access for the base model in your region (here a
Claude model in
us-east-1), enabled once in the Bedrock console. - One application inference profile per team, created by
copying the base system profile and tagging it for cost allocation. The
script below does this for each team in
$TEAMS. - Credentials the gateway can sign with, scoped to invoke
those profiles. Invoking an application inference profile needs
bedrock:InvokeModelon both the profile ARN and the underlying model, so a least-privilege policy lists both. This lab uses short-lived credentials held in a Kubernetes Secret.
bash scripts/03-aws-profiles.sh — one application inference profile per team
aws bedrock create-inference-profile --region us-east-1 \
--inference-profile-name agw-cost-finance \
--description "per team cost profiling for team finance" \
--model-source copyFrom=arn:aws:bedrock:us-east-1:<account-id>:inference-profile/us.anthropic.claude-haiku-4-5-20251001-v1:0 \
--tags key=team,value=finance key=cost-center,value=finance
# returns: arn:aws:bedrock:us-east-1:<account-id>:application-inference-profile/<id>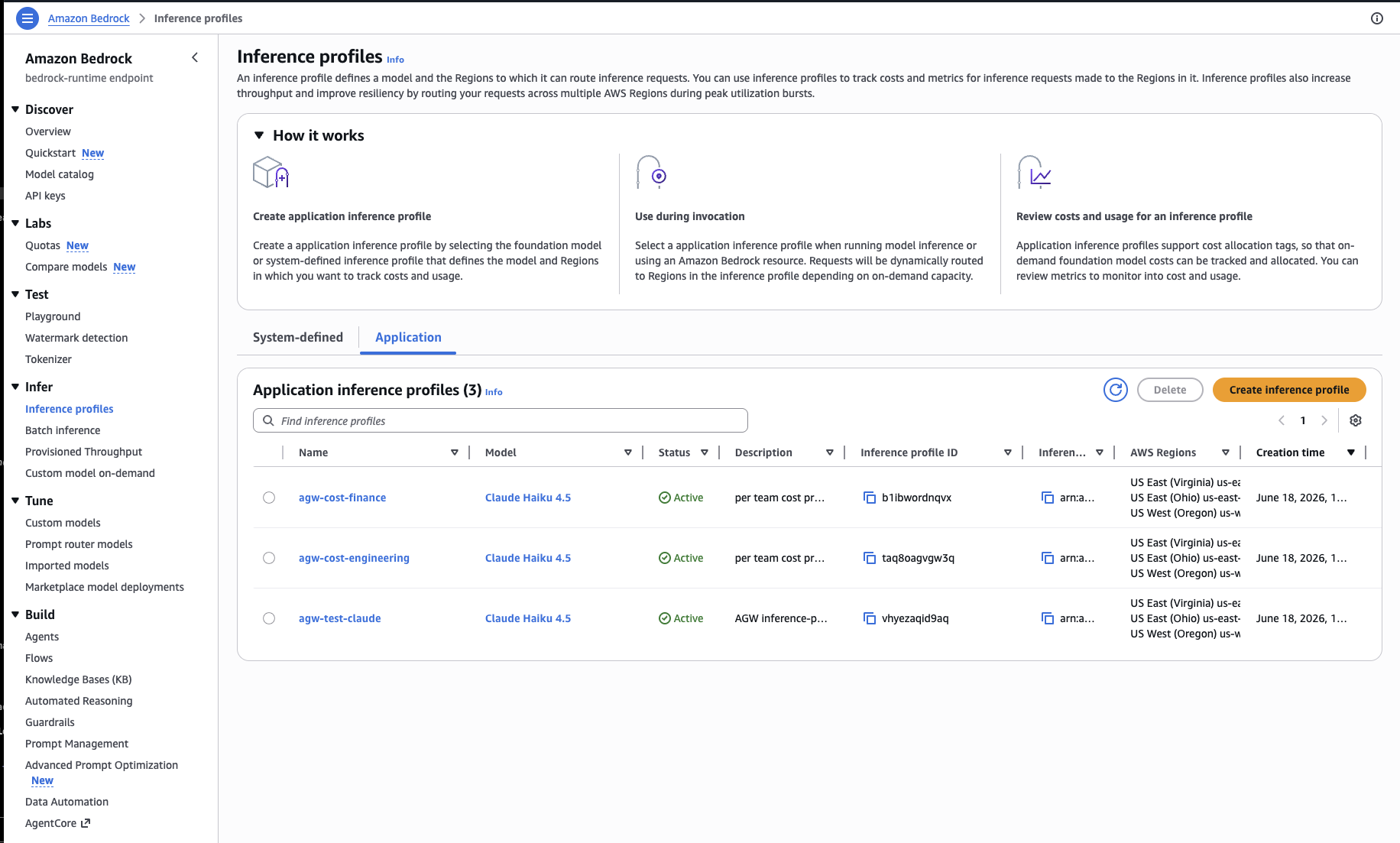
03-aws-profiles.sh runs: the two per-team application inference profiles (agw-cost-finance, agw-cost-engineering) show Active in the Amazon Bedrock console under Inference profiles, the Application tab, in us-east-1. Each carries its team's cost-allocation tags. Click to enlarge.The Solo deployment
The gateway side is one backend and one route, plus the credentials Secret. The
backend selects the bedrock provider and leaves the model unset,
which is what lets a single backend serve every team's profile: the model
comes from each request.
yaml yaml/backend-route.yaml — bedrock backend (model from request) + route
apiVersion: agentgateway.dev/v1alpha1
kind: AgentgatewayBackend
metadata:
name: bedrock
namespace: bedrock-cost
spec:
ai:
provider:
bedrock:
# model unset on purpose — taken from each request, so one backend
# serves every team's application-inference-profile ARN.
region: us-east-1
policies:
auth:
aws: # SigV4; the AWS auth path, not a bearer key
secretRef:
name: bedrock-secret
---
apiVersion: gateway.networking.k8s.io/v1
kind: HTTPRoute
metadata:
name: bedrock
namespace: bedrock-cost
spec:
parentRefs:
- name: agentgateway-proxy
namespace: agentgateway-system
rules:
- backendRefs:
- name: bedrock
namespace: bedrock-cost
group: agentgateway.dev
kind: AgentgatewayBackendbash scripts/04-backend.sh — the AWS credentials Secret
# The bedrock provider reads accessKey / secretKey / sessionToken from this Secret.
kubectl -n bedrock-cost create secret generic bedrock-secret \
--from-literal=accessKey="$AWS_ACCESS_KEY_ID" \
--from-literal=secretKey="$AWS_SECRET_ACCESS_KEY" \
--from-literal=sessionToken="$AWS_SESSION_TOKEN"403 "The security token included in the request is
invalid." The lab script restarts the proxy for you after writing the
Secret.
Run it
bash end to end on kind
aws sso login --profile <your-profile> # live AWS access is required
export AGENTGATEWAY_LICENSE_KEY="your-license-key"
./scripts/quick.sh up # cluster + agentgateway + per-team profiles + backend + smoke
./scripts/quick.sh test # asserts 200s and a per-team metric series
./scripts/quick.sh teardown # deletes the cluster and the AWS profiles
Each team sends the same chat-completions request, differing only in the
model field, which carries that team's profile ARN. The gateway
signs the call, invokes Bedrock over Converse, and returns the completion.
bash a request as team "finance"
curl localhost:8080/v1/chat/completions -H 'content-type: application/json' -d '{
"model": "arn:aws:bedrock:us-east-1:<account-id>:application-inference-profile/b1ibwordnqvx",
"messages": [{"role": "user", "content": "In one sentence, a tip for a finance microservice."}]
}'
# 200; the response echoes the same ARN as the model, with a usage block.Take the ARN off the client: select the team from its token
Sending the profile ARN in the request, as above, is fine for trying it out, but you do not want every client carrying its team's ARN. That leaks the team-to-ARN map into client code and breaks the moment you rotate a profile. The model identifier should be decided at the gateway from the caller's identity.
The important thing to understand: nothing rewrites the model.
There is no expression that turns one ARN into another. Each team is a
separate backend with its ARN fixed, and the token's
team claim only selects which backend the request
is routed to. Alice (team: finance) is routed to the finance
backend, which already holds the finance ARN; Bob (team: engineering)
is routed to the engineering backend, which holds the engineering ARN. The "team to ARN"
mapping is the set of backends plus the route rules, not a
substitution. (Application inference profile ARNs end in an opaque id like
gklxzm9bxup7, not the word "finance", so there is nothing to
compute from the claim anyway.)
So how does the team claim drive routing, when routes match
headers and not claims? agentgateway has no claims-to-headers field, so a JWT
policy in the PreRouting phase does it: in that phase the token
validation and a CEL transformation both run before
the route is chosen. The transformation projects the signed team
claim into the x-team header, and the HTTPRoute then matches on it.
Because set overwrites, any x-team the client tries to
send is replaced first. The client sends only its token:
yaml validate the token + project the team claim into the routing header
apiVersion: enterpriseagentgateway.solo.io/v1alpha1
kind: EnterpriseAgentgatewayPolicy
metadata:
name: bedrock-team-auth
namespace: agentgateway-system
spec:
targetRefs:
- group: gateway.networking.k8s.io
kind: Gateway
name: agentgateway-proxy
traffic:
phase: PreRouting # JWT check + transformation run BEFORE routing
jwtAuthentication:
mode: Strict
providers:
- issuer: bedrock-cost-lab
audiences: ["bedrock-api"]
jwks:
inline: |
{ "keys": [ ... ] } # your IdP's public JWKS
transformation:
request:
set:
- name: x-team
value: "jwt.team" # signed claim → routing header (overwrites any client value)
One declared backend per team, each with its ARN fixed, and one route rule per
team that matches on x-team. Switch tabs to see each team is just
a separate copy with a different name and a different fixed ARN:
apiVersion: agentgateway.dev/v1alpha1
kind: AgentgatewayBackend
metadata:
name: bedrock-finance
namespace: bedrock-cost
spec:
ai:
provider:
bedrock:
region: us-east-1
# the profile id is assigned by AWS at create time (see the console screenshot above); yours will differ
model: arn:aws:bedrock:us-east-1:<account-id>:application-inference-profile/b1ibwordnqvx
policies:
auth:
aws:
secretRef:
name: bedrock-secret
---
apiVersion: gateway.networking.k8s.io/v1
kind: HTTPRoute
metadata:
name: bedrock-finance
namespace: bedrock-cost
spec:
parentRefs:
- name: agentgateway-proxy
namespace: agentgateway-system
rules:
- matches:
- headers:
- name: x-team
value: finance # fires only for x-team: finance
backendRefs:
- name: bedrock-finance # → the backend above (finance ARN)
group: agentgateway.dev
kind: AgentgatewayBackend# Alice's client — just the token. No x-team, no ARN, no model.
TOKEN=$(./scripts/mint-token.sh finance) # claim: team=finance
curl localhost:8080/v1/chat/completions \
-H "Authorization: Bearer $TOKEN" \
-H 'content-type: application/json' \
-d '{"messages":[{"role":"user","content":"a tip for a finance service"}]}'
# gateway projects team=finance → x-team:finance → bedrock-finance → finance ARNapiVersion: agentgateway.dev/v1alpha1
kind: AgentgatewayBackend
metadata:
name: bedrock-engineering
namespace: bedrock-cost
spec:
ai:
provider:
bedrock:
region: us-east-1
# the profile id is assigned by AWS at create time (see the console screenshot above); yours will differ
model: arn:aws:bedrock:us-east-1:<account-id>:application-inference-profile/taq8oagvgw3q
policies:
auth:
aws:
secretRef:
name: bedrock-secret
---
apiVersion: gateway.networking.k8s.io/v1
kind: HTTPRoute
metadata:
name: bedrock-engineering
namespace: bedrock-cost
spec:
parentRefs:
- name: agentgateway-proxy
namespace: agentgateway-system
rules:
- matches:
- headers:
- name: x-team
value: engineering # fires only for x-team: engineering
backendRefs:
- name: bedrock-engineering # → the backend above (engineering ARN)
group: agentgateway.dev
kind: AgentgatewayBackend# Bob's client — same call, different token
TOKEN=$(./scripts/mint-token.sh engineering) # claim: team=engineering
curl localhost:8080/v1/chat/completions \
-H "Authorization: Bearer $TOKEN" \
-H 'content-type: application/json' \
-d '{"messages":[{"role":"user","content":"a tip for an engineering service"}]}'
# gateway projects team=engineering → x-team:engineering → bedrock-engineering → engineering ARNThis is the behaviour the lab verifies live:
| request | result |
|---|---|
| no token | 401 |
finance token, no team header | 200 → finance ARN |
engineering token, no team header | 200 → engineering ARN |
finance token + client sends x-team: engineering | still finance ARN (gateway overwrote the header) |
PreRouting phase is what makes it work: the JWT validation and
the set transformation both run before route selection, so the
gateway derives x-team from the signed team claim and
the HTTPRoute matches it. Because set overwrites, a client that
sends its own x-team has it replaced before routing and cannot
reach another team's profile. The same claim-to-header pattern (with the
gateway-side stripping) is shown for general API versioning in the
versioned cluster routing
lab. The ARN never appears on the client either way.
Cost, attributed per team
After traffic from both teams, the gateway's token metric carries one series per team, keyed by the team's profile ARN. This is a run from the lab: each team's usage is separate, and the profile ARN is the dimension you group by.
| team | model (gen_ai_request_model) | requests | output tokens |
|---|---|---|---|
| finance | …/application-inference-profile/b1ibwordnqvx | 7 | 184 |
| engineering | …/application-inference-profile/taq8oagvgw3q | 5 | 127 |
The metric records input, output and
input_cache_read token types per series, so a dashboard can show
tokens per team, and cost per team once you multiply by your price table.
promql per-team output tokens, last hour
sum by (gen_ai_request_model)(
increase(agentgateway_gen_ai_client_token_usage_sum{gen_ai_token_type="output"}[1h]))
For dollars rather than tokens, the same per-team split shows up in AWS. The
application inference profile's team tag is a cost-allocation tag,
so once activated it breaks out usage and cost per team in AWS Cost Explorer
and the Cost and Usage Report. Use the gateway metric for the real-time view
and AWS for the billed view; they agree because both key on the same profile.
Cleanup
./scripts/quick.sh teardown deletes the kind cluster and the
application inference profiles it created, so nothing lingers in the account.
Why put this in the gateway
Application inference profiles alone give you per-team cost in the AWS bill. A gateway in front of them adds the things a shared LLM path needs anyway and puts them in one place: the AWS credentials stay in the cluster rather than on each team's clients, the per-team token view is live instead of next-day, and the same gateway that meters the traffic is where authentication, guardrails and rate limits attach. One backend, one route, and a profile per team is all it takes to turn a single shared bill into per-team accounting.
Versions
Built and verified on both editions:
v1.3.0v1.5.1v2026.5.1v1.5.1